Sommaire
- Introduction
- Jeu de données
- Architecture
- Problèmes rencontrés
- Pistes d'amélioration
- Score du calculateur GreenIT
- Conclusion
Introduction
Ce site s’inscrit dans le contexte du Challenge OpenData proposé par l’Ensimag. Il vous offre la possibilité d’observer la répartition des produits du quotidien en ce qui concerne le nutri-score et l'éco-score.
Le nutri-score est un indicateur nutritionnel ayant pour but de favoriser le choix de produits sains et de participer à la lutte contre l’obésité, le diabète et les maladies cardiovasculaires. L’éco-score en est le cousin environnemental puisqu’il se concentre sur l’impact écologique d’un produit.
Si nous avions initialement voulu nous concentrer sur la visualisation de la part de recyclable dans notre quotidien, nous nous sommes finalement réorientés vers le nutri-score et l’éco-score qui nous semblent plus pertinents dans le cadre d’une étude de grande ampleur où les subtilités de recyclage ne pourraient être représentées et fausseraient les chiffres. Les deux indicateurs choisis nous permettent ainsi par une même représentation de couvrir à la fois le thème du développement durable et de la responsabilité civile imposés par le sujet. L'idée est donc de visualiser l’importance de la gamme des produits sains et responsables dans l’ensemble des choix du quotidien.
Jeu de données
Pour ce projet, nous avons utilisé OpenFoodFact. Nous voulions initialement nous servir de l’API OpenFoodFacts pour ne pas stocker la base de données dans l’application. Mais, nous avons eu quelques problèmes (mentionnés en partie IV). Nous nous sommes donc redirigés vers une solution plus classique, ou l’on stocke le jeu de données dans l’application. L’idée est d’avoir une liste en JavaScript regroupant toutes nos données.
Nous avons donc récupéré un fichier csv contenant plus d’un million de produits. Il fallait faire du prétraitement de données pour respecter la limite de taille de l’application. Nous avons tout d’abord sélectionné seulement les colonnes nous intéressant : les catégories, l’éco-score, le nutri-score,... Puis, nous avons établi une liste de 50 catégories pour trier les différents produits et faciliter le choix de catégorie pour l’utilisateur.
Nous avons supprimé les produits ne possédant pas de catégories, de pays de vente et d’indications énergétiques. Nous avons aussi encodé les noms de catégories et d’attributs, pour utiliser moins de caractères sur chaque donnée. À terme, cet encodage nous économise environ 30 Mo.
Enfin, nous avons supprimé 5 lignes sur 6, pour respecter la contrainte de taille de l’application. Nous avons un jeu de données comprenant environ 80 000 produits.
Architecture
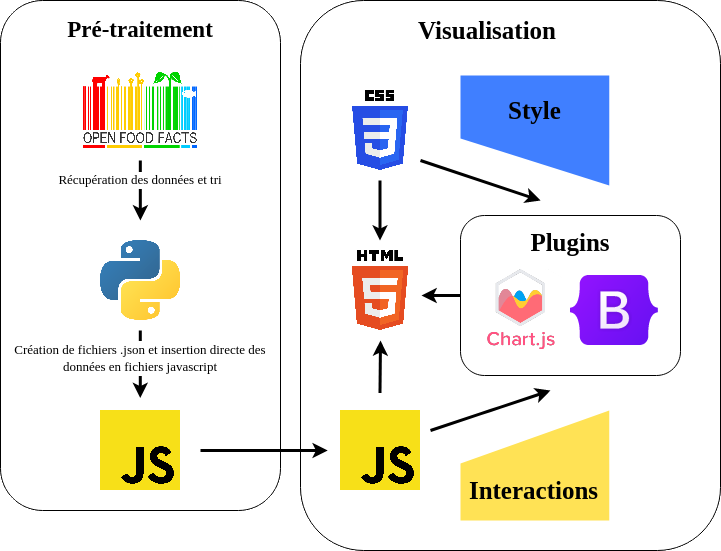
Problèmes rencontrés
Initialement, nous voulions utiliser l’API Web fournie par OpenFoodFacts à la volée, en faisant des appels au site à chaque fois que nous effectuons une recherche. Avant même de commencer, nous savions qu’il y aurait quelques problèmes de performance mais le but d’utiliser cette API était de réduire la taille de notre site en délaissant le stockage des données, le tout pour ne pas dépasser la limite des 10 Mo.
En premier lieu, nous avions réussi à avoir une liste de produits triés par pays et par catégorie en utilisant l’API de recherche simple d’OpenFoodFacts, mais nous ne pouvions en avoir que 24 par requête qui durent chacune 300ms, ce qui peut paraître peu mais en réalité est énorme si nous voulions récupérer la liste des “seulement” 1900 pizzas en France, et encore pire si un des filtres (catégorie ou pays) était absent, ce qui aurait donné un nombre indécent de produits et aurait mené à des temps de chargements de plusieurs minutes pour notre site.
En effet, cette API de recherche simple marche ainsi : Une requête est envoyée à `https://world.openfoodfacts.org/country/"nom_du_pays"/category/"nom_de_la_categorie"/"numero_de_page".json`, qui renvoie un fichier json qui possède 24 entrées tout en indiquant le nombre total de produits obtensible. Une solution que nous avons examinée est d’augmenter le nombre de produits par page, mais ce n’était pas possible avec l’API de recherche simple du site.
Nous avons donc utilisé l’API de recherche avancée qui permet donc d’avoir plus d’options et qui marche relativement de la même façon, avec ce genre de requêtes : `https://world.openfoodfacts.org/cgi/search.pl?action=process&page_size="taille_de_la_page"&sort_by=product_name&tagtype_0=categories&tag_contains_0=contains& tag_0="nom_de_la_categorie"&tagtype_0=country&tag_contains_0=contains&tag_0="nom_du_pays"&page="numero_de _la_page"&json=1`. Le grand avantage de cette recherche est qu’elle peut nous donner accès à un nombre de résultats beaucoup plus grand.
Cependant, l’API d’OpenFoodFacts n’a pas été conçue pour être utilisée intensivement par des applications faisant du Big-Data, et même avec nous améliorations elle restait relativement lente. De plus, lorsque nous faisions des requêtes avec une taille de page gigantesque, le site rejetait notre demande en nous mettant une erreur CORS `Cross Origin Resource Sharing’, ce qui est un protocole fait pour empêcher des transferts de données non locaux. C’était sans aucun doute une sécurité anti DDOS qui activait cette option lors de transferts de données trop importants à l’API, qui pouvait être contournée en ajoutant notre origine dans l’User-Agent de notre requête, mais n’ayant pas fait de Web sans serveur avec du javascript auparavant et dû à la limite de temps, nous avons décidé d’abandonner cette solution.
En second recours, nous voulions utiliser des fichiers “.csv” qui étaient stockés en local et qui contenaient une version très compressée de la base de données (qui pesait initialement 4,5 Go) que nous avons pré traitée. Cependant, dû à une politique de sécurité relativement récente des navigateurs, le protocole “file://” qui permet un accès direct à des fichiers locaux est considéré comme un Cross Origin Resource Sharing, et ne peut donc pas être accédé. Cette restriction aurait pu être contournée en utilisant notre application comme un serveur local, mais étant donné la spécification de notre application, c’était impossible. Nous avons donc dû se résigner à une technique secrète et interdite par trois des dix commandements des saintes écritures de l’église du javascript : Créer un fichier json qui contient les données de notre base avec une syntaxe proche de la déclaration d’un dictionnaire en javascript, enlever les lettres ‘on’ de l’extension ‘.json’, puis ajouter “let nom_variable = “ au début du fichier pour pouvoir utiliser ce fichier comme un script javascript, puis ajouter le code de la désencryption du nom des catégories dans ce même fichier. Le passage au format JSON a augmenté la taille prévue du fichier comparé à un fichier CSV, mais grâce à nos efforts de compression ce n’est pas tant impactant que cela.
Pistes d'amélioration
Une amélioration possible est d’augmenter le nombre de données, pour avoir des mesures un peu plus précises. On peut encore gagner de la place dans les données en encodant les noms de pays, comme pour les catégories. Cependant, cela peut poser des problèmes si l’on ajoute des données et un nouveau pays qui n’est pas encodé. De plus, ce travail d’encodage est long et très redondant, ce qui peut entraîner rapidement une erreur
D’un point de vue visualisation, il pourrait être intéressant de représenter les diagrammes circulaires sur une carte du monde afin de peut-être mettre en avant une corrélation entre l’éco-score et la région du monde de production par exemple. Toutefois, cette façon de faire pourrait également perdre l’usager du site. C’est donc une piste à étudier mais pas forcément à mettre en place.
Score du calculateur GreenIT
Pour les pages web annexes de l'application (page d'accueil, page de contexte et rapport), nous avons obtenu pour les 3 pages la note A, avec un EcoIndex compris entre 85 et 90. C'est un bon score, ce qui est normal car ces pages ne sont composées que d'HTML et de CSS basiques. Il y a très peu de javascript et requêtes effectuées.
Pour la page affichant les données, nous avons obtenu la note de B avec un EcoIndex de 73.93. Ce résultat est plutôt bon. Il s’explique en partie du fait qu’on a stocké les données en locale, ce qui évite d’effectuer beaucoup de requêtes HTTP à une API. Dans les pistes d’améliorations données par l’analyseur, un axe qui est revenu souvent est la minimisation des fichiers javascript et css pour enlever les espaces et les sauts de lignes inutiles.
Conclusion
Dans l’ensemble, ce projet nous a permis de développer de nombreuses compétences transverses et faire des rappels de web depuis le projet de 2ème année. L’organisation du travail n’a pas été parfaite avec notamment la gestion du contrôleur qui s’est entamé tard dans le projet et a ralenti le processus. Toutefois, nous ressortons grandi.e.s de cette expérience avec la satisfaction d’avoir encore appris des savoirs nouveaux.