RAPPORT CHALLENGE OPEN DATA
Matthieu Petit, Hugo Pons, Joao Vitor Vargas Soares, Benjamin Cararo, Mathis Lavigne
Notre page web présente la situation actuelle des accidents automobiles en France, selon les départements, l’heure et quelques autres facteurs sous forme de diagrammes. Elle a pour objectif de voir si les règles de sécurité (port de la ceinture, vitesse maximale autorisée…) ont un réel impact sur la gravité des accidents (proportion d’accidents graves|bénins).
1. Source des données
Les données principales sur les accidents que nous avons sélectionnées proviennent de Data.Gouv, un service public français placé sous l’autorité du premier ministre qui diffuse des données publiques de l’Etat. En particulier, ce sont les bases de données annuelles des accidents corporels de circulation routière en 2019, publiées par le Ministère de l’Intérieur, qui nous intéressent.
Liens
Ces fichiers listent tous les accidents saisis par les forces de l’ordre qui ont eu lieu au cours des années 2005 à 2019, avec de nombreux paramètres disponibles : l’heure, le département, les coordonnées GPS, le type de véhicule, le type de voie, la luminosité…
Nous les avons aussi croisées avec d’autres données précises sur les départements français: https://france-geojson.gregoiredavid.fr/ pour l’affichage des cartes des régions et départements, et https://www.insee.fr/fr/statistiques/4989753?sommaire=4989761 pour les populations. De même, nous avons récupéré des données sur les arrondissement de Paris :
https://www.data.gouv.fr/fr/datasets/arrondissements-1/ (carte)
https://94.citoyens.com/2019/population-2019-a-paris-par-arrondissement,07-01-2019.html (population par arrondissement).
Fichiers originaux utilisés
caracteristiques-2019.csv
usagers-2019.csv
lieux-2019.csv
population.csv
departments.json
arrondissements_paris.geojson
2. Traitement
Trois scripts Python (avec les bibliothèques Pandas et Csv), et deux scripts NodeJS (avec la bibliothèque csv-parse) nous ont permis de traiter les données pour nos interprétations.
Un premier pré-traitement des données a été réalisé avec Python, afin de retirer les colonnes inutiles des fichiers caracteristiques-2019.csv et population.csv. Ensuite, nous avons calculé le nombre d’accidents total par région, valeurs qui ont été ajoutées dans une nouvelle colonne au fichier population.csv (infos des départements) pour obtenir des données proportionnelles au nombre d’habitants.
Pour le graphe des accidents en fonction de l’heure et du département sélectionné, un script NodeJS se charge de créer un dictionnaire ayant pour clés chaque département et arrondissement, et en valeur un tableau vide de 24 cases. Puis, on récupère le département et l’heure à laquelle se produit chaque accident, pour l’ajouter dans le dictionnaire avec la bonne clé, et l’heure comme index pour le tableau de valeurs. En sortie, le dictionnaire est affiché en format JSON.
Pour le graphe de gravité de blessure en fonction du département sélectionné, un autre script NodeJS créé le même dictionnaire que précédemment, mais ayant pour valeur un tableau vide de 4 cases. Pour chaque accident, on récupère le département en clé, et gravité de l’accident sur une échelle de 0 à 3, qui va servir d’index pour la valeur de l’entrée du dictionnaire. La sortie est aussi un dictionnaire en JSON.
Dans un second temps, un autre script Python s’occupe de rassembler, pour chaque département, le nombre d’accidents par tranche de vitesse maximale autorisée (vma - limitation de vitesse) dans le fichier vmaData.csv. Un script du même type génère un autre fichier csv du nombre d’accidents par tranche de vma, mais cette fois-ci en séparant à chaque fois les accidents selon la gravité (de 0 à 3).
Enfin, un dernier script python s’occupe de lier les données relatives aux accidents en fonction de la Vitesse Maximale Autorisée avec la gravité des dommages corporels causés (Indemne, blessé léger, blessé grave, décès).
Ces scripts de pré-traitement permettent d’alléger considérablement le chargement de la page web et permettent ainsi d’éviter les calculs inutiles.
3. Architecture et technologies
Le site utilise d3js pour la représentation de la carte de France et le tracé des départements et arrondissements, à l’aide des données geojson.
Pour ce qui est des graphes, la librairie ChartJS est utilisée.
Les données des fichiers csv, json et geojson sont tous hébergés sur GitHub, qui nous sert de CDN pour ce projet.
Concernant l’architecture du site, nous avons choisi de séparer l’écran en 2 parties distinctes. Sur la gauche, une carte des départements français, et sur la droite la liste des graphes.
Quand on clique sur un département, les données et les graphiques représentés à droite s’actualisent.
Le tutoriel suivant a été utilisé pour réaliser le zoom sur le département choisi : Zoom to Bounding Box II.
Pour l’affichage de la carte de France, nous nous sommes inspirés de celui-ci : D3JS - Création d'une carte choroplèthe.
Nous avons aussi décidé de séparer le code qui permet d’instancier et actualiser chaque graphe, dans des scripts JS distincts afin de pouvoir travailler de façon individuelle plus facilement. En effet, chaque graphe est composé d’une fonction d’instanciation et de mise à jour.
Tous les accidents, représentés par des points, étant trop lourds à afficher en même temps sur la carte de France, nous avons choisi de les présenter seulement lorsqu’un département est cliqué.
De plus, le département de Paris comportant aussi trop d’accidents pour les représenter en même temps, nous avons ajouté le tracé des arrondissements parisiens pour alléger le traitement des données, et avoir une représentation plus précise.
4. Analyse Green IT
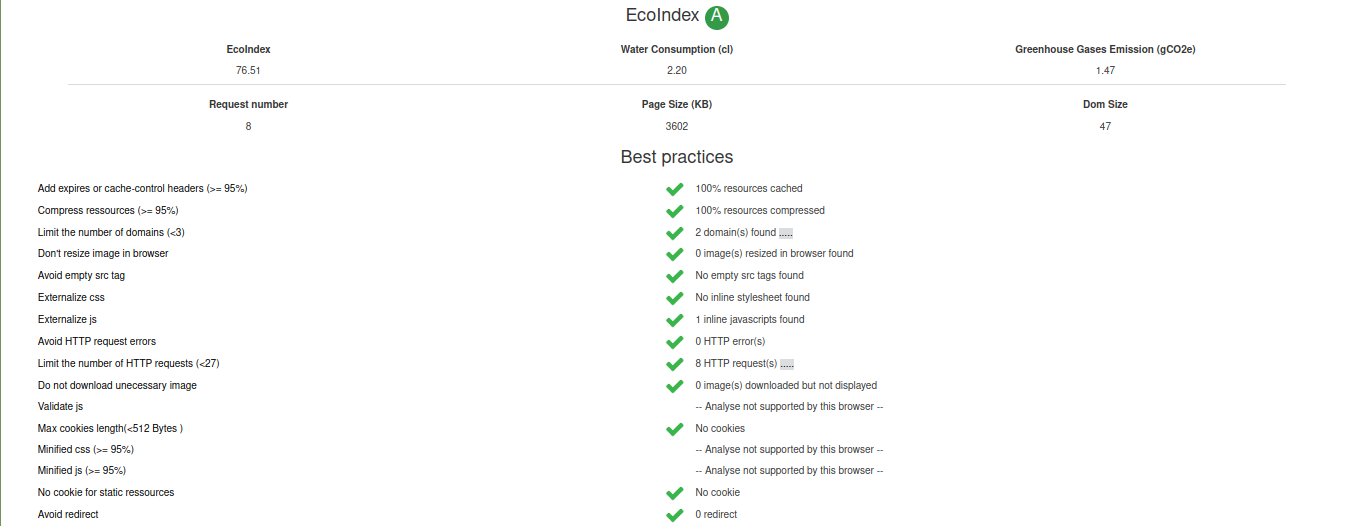
L’analyse Green IT a été réalisée via Mozilla Firefox 92.0.1 sous Linux Mint 20.2.
L’extension utilisée s’appelle GreenIT Analysis V2.2.0. Le GitHub de l’extension est situé à cette adresse : cnumr/GreenIT-Analysis: GreenIT-Analysis
Nous avons fait en sorte de supprimer toutes les croix rouges et oranges. Après optimisation du site, nous avons réussi à avoir un EcoIndex A et 100% de cases vertes.
L’image suivante montre le rapport complet de Green IT :