Introduction
Bien que l'épidémie du COVID-19 semble atteindre tous pays du monde, son impact n'est pas homogène. Le but de notre outil de visualisation est d'essayer de trouver s'il existe des corrélations insoupçonnées entre les divers indicateurs socio-économiques des pays du monde, et les conséquences de cette pandémie sur ceux-ci.
Jeux de données choisis
Pour alimenter notre outil, nous avons utilisé plusieurs jeux de données ouvertes de provenances diverses :
-
Indicateurs quantitatifs
-
Total de population par pays, Banque Mondiale
-
PIB, PIB par habitant et accroissement du PIB (%), Heritage Foundation
-
-
Indicateurs socio-économiques
-
Bien être + Espérance de vie + inégalités + emprunte, Happy Planet Index
-
Indice de développement humain, UNDP
-
État global de joie, World Hapiness Index
-
Dépenses de santé courante en %, Mondiale
-
Dépenses de santé courante par habitant, Banque Mondiale
-
Emploi (en %), score des dépenses publiques, Heritage Foundation
-
Index de liberté de la presse, Reporters without borders
-
Stabilité politique et absence de violence, Qualité du service publique, Niveau de politique soutenant les secteurs privés, Contrôle de la corruption, Banque Mondiale
-
Score d'efficacité judiciaire, Heritage Foundation
-
Score d'intégrité du gouvernement, Heritage Foundation
-
Score de droit à la propriété, Heritage Foundation
-
Score de charge fiscale, Heritage Foundation
-
Score de liberté financière et liberté économique globale, Heritage Foundation
-
Proportion de sièges occupés par des femmes dans les parlements nationaux (%), Banque Mondiale
-
-
Jeux de données COVID-19
- Toutes les données concernant la pandémie du COVID-19 ont été prises sur le git de Our World in Data
Format de visualisation
Comme notre outil de visualisation a pour but de comparer les pays entre eux, deux choix s'offraient à nous : soit une carte, soit un graphe à bulles. Nous avons opté pour la première option, car celle-ci permet mieux de mettre en évidence des corrélations, tandis que l'autre joue un rôle plus informatif. Nous nous sommes inspirés des nombreux graphes de ce format présentant des données sur les pays du monde, par exemple pour l'idée d'avoir une couleur par continent.
Technologies utilisées et architecture
1. Traitement des données
Afin de pouvoir utiliser les données dans notre outil de visualisation, nous avons d'abord
choisi de prétraiter les données brutes afin d'extraire, trier, classer, convertir et mettre
au bon format celles qui nous intéressent.
Pour cela, nous avons mis au point une application python en ligne de commande. celle-ci
prend en entrée un fichier de configuration json, dont voici le format :
// config.json { "csv/Political_StabilityNoViolence.csv": { // Nom du fichier "dump_lines": 14, // Nombre de lignes à ignorer au début "encoding": "iso-8859-1", // Format d'encodage du fichier "delimiter": ";", // Délimiteur des colonnes du fichier .csv "country_name": "Country/Territory", "dot": ",", // Colonne contenant les noms de pays "grandeur_1": [ // Grandeurs a utiliser en abscisse du graphe a bulles { "name": "Rank", // Colonne contenant la grandeur "new_name": "Rang d'instabilité politique", // Renommage/traduction "description": null // Descriptif de la grandeur }, ... ], "grandeur_2": [], "grandeur_3": [] }, ... }
Cette méthode permet de traiter plusieurs fichiers de données aux formats différents en même temps, tout en minimisant le code à écrire pour chaque fichier.
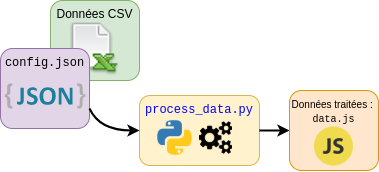
Pour stocker les données traitées localement, tout en contournant le problème du CORS
(Cross-Origin Resource Sharing) dans la page web de visualisation, les données
traitées ne sont pas stockées dans un fichier json mais dans un script javascript
où des variables contenant ces données sont déclarées :
// data.js const data = [ { "country_name": "Afghanistan", "ISO-name": "AFG", "continent": "Asia", "grandeur_1": { "% des dépenses publiques en santé": 9.39572716, ... }, ... }, ... ] const data_bounds = { "grandeur_1": [ { "name": "Droit à la propriété", "description": "", "min": 7.5, "max": 97.5 }, ... ], ... }
-
Le script python utilise les bibliothèques suivantes :
-
country-converter pour rechercher et normaliser les noms des pays mais également pour obtenir des infomations complémentaires (continent et nom ISO-3)
-
argparse pour l'interface en ligne de commande.
-
2. Interface, lecture des données et affichage
Pour l'affichage des données, nous avons donc choisi d'utiliser la bibliothèque
D3.js pour concevoir un graphe a bulles interactif et animé permettant de
visualiser chaque pays du monde. Bien entendu, le code javascript utilise comme données
celles traitées par le script python au préalable.
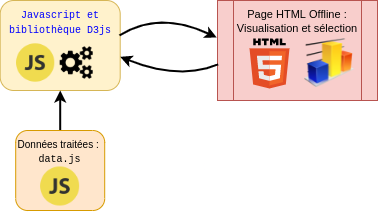
Enfin, la page web utilisée comme interface est alimentée de quelques scripts utilisant des
fonctionnalités de jQuery pour le style et l'interactivité.
Méthodes de conception et choix de design
Puisque ce projet a nécéssité la familiarisation rapide avec des concepts et des technologies
que nous n'avions pas ou peu utilisé auparavant (javascript, D3.js,
jquery, manipulation de fichiers csv et json en
python...), nous avons beaucoup employé la méthode du peer programming pour
diviser les taches de lecture de documentation, d'expérimentation avec le code et de
programmation de l'application.
Conformément aux lignes directrices de choix de conception des outils de visualisation, nous avons choisi d'utiliser les palettes de couleurs conçues par le chercheur en médecine Martin Krzywinski, édudié pour être adapté à plusieures formes de daltonisme.
De plus, nous avons analysé l'empreinte environnementale de notre outil grâce à GreenIT-analysis. Le bilan de cet outil nous a confirmé que l'impact écologique notre projet est quasiment inexistant. Ce résultat n'est cependant ni étonnant ni impressionnant, puisque l'outil de visualisation ne dépend d'aucune ressource non hébergée localement hormis quelques bibliothèques javascript, et donc ne nécéssite peu voir aucune bande passante; nous n'avons donc pas eu de choix ou de compromis à faire pour réduire l'impact environnemental.
Difficultés rencontrées
La principale difficulté rencontrée lors de la conception du script de traitement des données
fut la gestion des différences entre les nombreux fichiers csv utilisés pour
alimenter l'outil de visualisation. De nombreux paramètres on été pris en compte, pour
tenter de créer un script permettant de traiter n'importe quel tableau présentant des
données triées par pays, et ce script semble être satisfaisant pour les données choisies.
Cependant, il est possible qu'ajouter d'autres données exige d'effectuer des modifications à
celui-ci.
Concernant la visualisation des données avec la bibliothèque D3.js, le principal
obstacle a été de permettre à notre seul graphe interactif de visualiser tous les jeux de
données utilisés tout en restant propre, lisible et esthétique. En effet, certaines de nos
données étaient indisponibles pour certains pays, ce qui rendait complexe l'implémentation
des transitions lors de la sélection des grandeurs à représenter. Heureusement,
D3.js étant une bibliothèque très flexible, ces problèmes ont pu être résolus
avec quelques workarounds.