BACHETARZI Angie, DUVET Youri, NGWE NDJOCK Jemima Paola, ODEH Majd, VIOGNE Florent
Avant de pouvoir faire n’importe quel traitement automatique sur les données, nous avons dû les rendre utilisables.
Les différents jeux de données récupérés de l'étude INCA comprennent pour chaque caractère spécial (ex : à, é, è, û), le caractère de contrôle unicode de remplacement. C'est pour cela que la première tâche laborieuse a été le remplacement de tous ces caractères par les bons ( ex: “Marque Rep#re” devient “Marque Repère”).
Une fois les jeux de données rendus utilisables, il nous fallait transformer ces données en un format utilisables par les librairies graphiques en JavaScript. Le format JSON étant un format très utilisé en JavaScript nous avons fait un analyseur en Python afin de convertir les données au format CSV au format JSON. Notre analyseur ne permettait pas seulement la transformation d'un format à un autre mais aussi la conversion de certaines informations comprises dans la notice d'utilisation des jeux de données (ex : les énumérations prennent la valeur de la notice).
Le fichier JSON obtenu après la phase de pré-traitement contenait beaucoup d’informations sur plusieurs types d’aliments dont nous n’avions pas besoin pour notre étude. Nous avons donc extrait les données qui nous intéressaient à savoir les données relatives à la consommation du pain, du lait, de la viande et des pâtes alimentaires et nous les avons stockées dans des fichiers JSON peu volumineux en utilisant jupyter lab. Ces fichiers nous ont permis de faire des affichages sur le type et la quantité de ces aliments de façon indépendante et en minimisant le temps de calcul.
Malgré les données transformées en JSON les fichiers étaient trop grands jusqu’à 156 Mo pour certains fichiers et les formats JSON n'étaient pas exactement ceux attendus par la librairie graphique . Ainsi nous avons eu une étape d’optimisation et de formatage des fichiers JSON. Cette étape consistait à extraire les informations importantes et les résumer dans des fichiers plus petits avant de les passer à la librairie graphique, et ces fichiers sont sous un format JSON unique selon chaque diagramme. Cette démarche nous a permis de fluidifier l’affichage et d'éviter de faire beaucoup de calculs sur des grands fichiers lors du chaque chargement de la page de visualisation.
Lien des jeux de données :
Données de consommations et habitudes alimentaires
Nous avons choisi de travailler avec un jeu de données sur la consommation et les habitudes alimentaires de la population en France métropolitaine.
Ces données sont fournies par l'ANSES (agence nationale de sécurité sanitaire, de l'alimentation, de l'environnement et du travail), et établies dans le cadre d’une étude INCA.
Plusieurs thématiques sont intégrées aux données (caractéristiques des individus ayant participé, critères de choix des aliments, préparation et conservation des aliments, ...)
Pour ce projet, nous avons décidé de nous focaliser sur deux thématiques principales : les caractéristiques des participants et leur consommation d’aliments en tout genre.
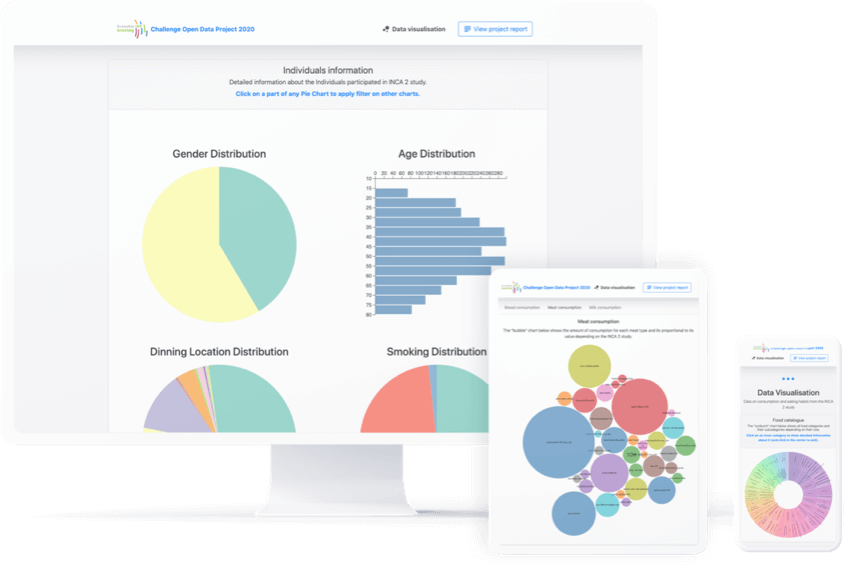
Dans un premier temps, dans le but d’avoir une idée générale sur les aliments consommés et leur fréquence de consommation, un catalogue alimentaire a été réalisé.
Il est possible de cliquer sur une catégorie d’aliment afin d’avoir accès aux sous-catégories de celle-ci.
Le jeu de données fournit des informations assez précises sur les participants de l’étude. Parmi ces informations, nous avons sélectionné celles que nous avons jugées les plus pertinentes pour répondre à nos demandes, comme l’âge, le sexe, le lieu du repas et si la personne est fumeuse ou non et à quelle fréquence celle-ci l’est.
Pour donner un aperçu de la population représentée, nous avons décidé de fournir 4 diagrammes permettant d’avoir une idée générale sur chacun de ces critères. Ces diagrammes sont dynamiques ; on peut cliquer sur une des catégories d’un diagramme circulaire pour afficher seulement les infos sur les personnes de cette catégorie. On peut aussi cliquer sur plusieurs diagrammes pour avoir les données sur une population plus précise ; par exemple, l’âge et le lieu du repas pour les femmes qui fument occasionnellement.
Ensuite, nous avons choisi de nous intéresser à trois types d’aliments distincts que les participants consomment : le pain, le lait et la viande.
Par exemple pour l’aliment “pain”, quelle est la proportion de personnes consommant du pain complet comparée aux personnes consommant du pain de mie. Et ce pour toutes les espèces de pain mentionnées dans l’étude.
Interface adaptatif (en utilisant Bootstrap 4)
Pour l’architecture nous avons séparé le projet en 2 parties :
 |
HTML, CSS : pour la construction des pages web. JavaScript : pour l'exploitation et la visualisation des données. |
|---|---|
 |
JQuery : est une librairie javascript pour simplifier la gestion du DOM HTML. |
 |
Bootstrap 4 est un framework front-end ( HTML5, CSS et JavaScript) spécialement conçu pour le développement d'application web responsive. |
 |
D3.js est une bibliothèque graphique JavaScript qui permet l'affichage de données numériques sous une forme graphique et dynamique (Data Visualisation). |
 |
CSV + JSON : pour les jeux de données (Data). |
 |
Python : Langage interprété que nous allons l’utiliser pour prétraiter les jeux de données utilisées |